Free apps for event studies and news analytics
EventStudyTools helps you perform event studies and news analytics analyses. Its research apps calculate all metrics needed for scientific publications (see sample results) of return and volume event studies, focused on single or multiple events.
You can access the research apps for free via the graphical user interfaces on this website, e.g., here for the abnormal return calculator. Please cite us accordingly.
The apps were built for our own research efforts and therefore offer access to new event study test statistic methods (e.g., this permutation test).
Use our Award-winning research apps!
Explore how you can make your research more innovative with our research apps and review publications that cite us on Google Scholar - such as this A+ ranked article.
How to perform an event study?
General Instructions For ARC
Error Handling
Why our research apps
- As scholars, we know what it takes to get published - we build our research capabilities for this purpose and share them here with you
- Our apps are easy to use via a graphical user interface (GUI) directly on this website, without any need for coding
- You get all the test statistics needed for your publication
- Using the apps is free of charge, however, limited in terms of requests to protect our server from spam requests
- Institutional access bypasses this protection, yet requires free whitelisting
- Full privacy. No personal data is stored. Only the hash value of your email is (temporarily) kept to prevent spam requests to our forms
- Further details about access, the required input files, and how to interpret the produced results can be found on our FAQ page - note: individual support is not possible
Watch the Chinese version of this introduction on YouTube.
Features of abnormal return calculator
- Ideal for sample studies: In one analysis run, you can study a large number of events at different dates and cluster them by sub-groups
- Large choice of expected return models, including the market model and various multi-factor models
- Test statistics at the AR-, CAR-, AAR-, and CAAR-levels
- P-values for all test statistics to assess significance levels
- Our results include novel permutation tests
- Validated against other solutions and published research papers
- Automatic adjustments for non-trading event dates, for example, an automatic switch to the subsequent trading day
- You can choose between simple and log returns
- Data file compilation service to help you create your input data files
- Free basic abnormal return calculator (bARC) to try out the analysis process through our GUI
- Market Model
- Market Adjusted
- Comparison Period Mean Adjusted
- Capital Asset Pricing Model (CAPM)
- Fama-French 3 Factor Model
- Fama-French-Momentum 4 Factor Model
- Fama-French 5 Factor Model
- T Test
- Cross-Sectional T
- Crude Dependence Adjustment T
- Patell Z
- Adjusted Patell Z
- BMP/Standardized Cross-Sectional Test
- Adjusted Standardized Cross-Sectional Test
- Skewness Corrected
- Rank Z
- Generalized Rank Z
- Generalized Rank T
- Sign Z
- Generalized Sign Z
- Wilcoxon
- Permutation Tests
- Automatic non-trading day adjustments
- Choice between simple and log-returns
- Optional data file creation service
Workflow for an event study when using our web interface
Performing event studies with EventStudyTools is simple. You only need to parameterize your analysis and upload the financial data (example), which you can retrieve at one of the free financial data providers (e.g., Yahoo!Finance). EST then does the work and sends you the results to your email, incl. all test statistics needed for publishing your work (example). Figure 1 illustrates this workflow. We offer three event study apps: An abnormal return calculator (ARC) for return event studies and an abnormal volume calculator (AVC) for event studies on trading volumes.

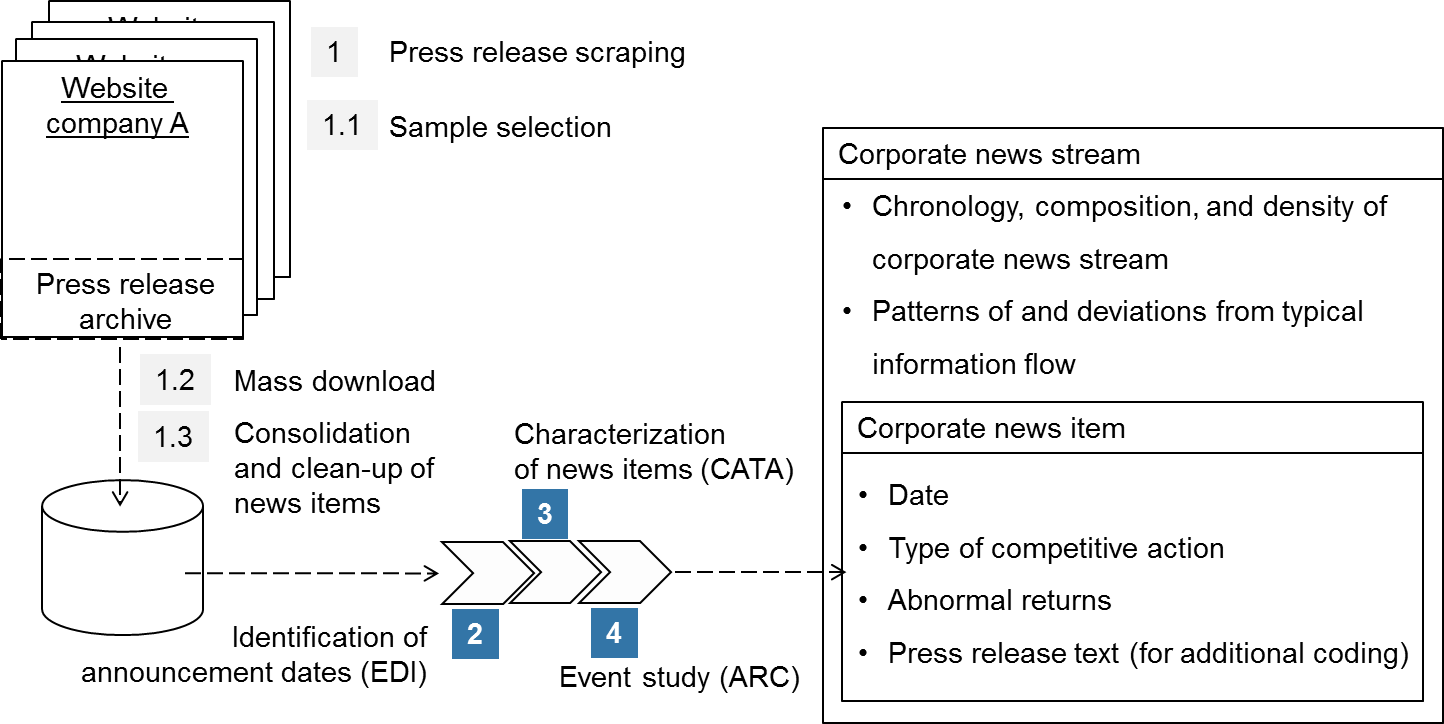
News Analytics
News analytics describes the analysis of news streams aimed at turning news into quantitative metrics and time-series. As a quantitative research approach, news analytics can be well combined with event studies that capture the market responses to the corresponding news. This combination of methods also has practical applications, such as news-based trading or peer group monitoring. The below figure illustrates the news analytics capabilities available to you on EventStudyTools.